| CONTENTS |
In this chapter, we get to the heart of Java and explore the object-oriented aspects of the language. The term object-oriented design refers to the art of decomposing an application into some number of objects, self-contained application components that work together. The goal is to break your problem down into a number of smaller problems that are simpler and easier to handle and maintain. Object-based designs have proven themselves over the years, and object-based languages such as Java provide a strong foundation for writing very small to very large applications. Java was designed from the ground up to be an object-oriented language, and all the Java APIs and libraries are built around solid object-based design patterns.
An object design "methodology" is a system or a set of rules created to help you break down your application into objects. Often this means mapping real-world entities and concepts (sometimes called the "problem domain") into application components. Various methodologies attempt to help you factor your application into a good set of reusable objects. This is good in principle, but the problem is that good object-oriented design is still more art than science. While you can learn from the various off-the-shelf design methodologies, none of them will help you in all situations. The truth is that there is no substitute for experience.
We won't try to push you into a particular methodology here; there are shelves full of books to do that.[1]
Instead, we'll just provide some common sense hints to get you started. The following general design guidelines will hopefully make more sense after you've read this and the next chapter.
Hide as much of your implementation as possible. Never expose more of the internals of an object than you have to. This is key to building maintainable, reusable code. Avoid public variables in your objects, with the possible exception of constants. Instead define accessor methods to set and return values (even if they are simple types). Later, when you need to, you'll be able to modify and extend the behavior of your objects without breaking other classes that rely on them.
Specialize objects only when you have to—use composition instead of inheritance. When you use an object in its existing form, as a piece of a new object, you are composing objects. When you change or refine the behavior of an object (by subclassing), you are using inheritance. You should try to reuse objects by composition rather than inheritance whenever possible, because when you compose objects, you are taking full advantage of existing tools. Inheritance involves breaking down the barrier of an object and should be done only when there's a real advantage. Ask yourself if you really need to inherit the whole public interface of an object (do you want to be a "kind" of that object) or if you can just delegate certain jobs to the object and use it by composition.
Minimize relationships between objects and try to organize related objects in packages. Objects that work closely together can be grouped using Java packages, which can hide those that are not of general interest. Think about how much work it would take to make your objects generally useful, outside of your current application. You may save yourself a lot of time later.
Classes are the building blocks of a Java application. A class can contain methods (functions), variables, initialization code, and, as we'll discuss later on, even other classes. It serves as a blueprint for making class instances, which are runtime objects that implement the class structure. You declare a class with the class keyword. Methods and variables of the class appear inside the braces of the class declaration:
class Pendulum {
float mass;
float length = 1.0;
int cycles;
float getPosition ( float time ) {
...
}
...
}
The Pendulum class contains three variables: mass, length, and cycles. It also defines a method called getPosition(), which takes a float value as an argument and returns a float value as a result. Variables and method declarations can appear in any order, but variable initializers can't make "forward references" to other variables that appear later. Once we've defined the Pendulum class, we can create a Pendulum object (an instance of that class) as follows:
Pendulum p; p = new Pendulum( );
Recall that our declaration of the variable p doesn't create a Pendulum object; it simply creates a variable that refers to an object of type Pendulum. We still have to create the object, using the new keyword. Now that we've created a Pendulum object, we can access its variables and methods, as we've already seen many times:
p.mass = 5.0; float pos = p.getPosition( 1.0 );
Two kinds of variables can be defined in a class: instance variables and static variables . Every object instance has its own set of instance variables; the values of these variables in one object can differ from the values in another object. We'll talk about static variables later, which, in contrast, are shared among all instances of an object. In either case, if you don't initialize a variable when you declare it, it's given a default value appropriate for its type (null, zero, or false).
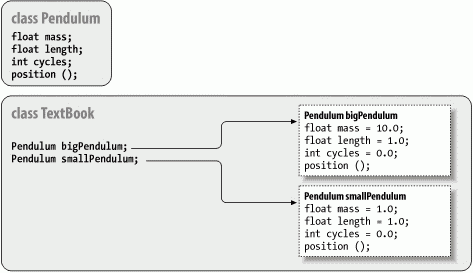
Figure 5-1 shows a hypothetical TextBook application that uses two instances of Pendulum through the reference-type variables bigPendulum and smallPendulum. Each of these Pendulum objects has its own copy of mass, length, and cycles. As with variables, methods defined in a class may be instance methods or static methods. An instance method is associated with an instance of the class, but the relationship isn't quite as simple as for variables. Instance methods are accessed through an object instance, but the object doesn't have its own copy of the methods (there is no duplication of code). Instead, the association means that instance methods can "see" and operate on the values of the instance variables of the object. As you'll see in Chapter 6 when we talk about subclassing; there's more to learn about how methods see variables. In that chapter we'll also discuss how instance methods can be "overridden" in child classes—a very important feature of object-oriented design. Both aspect differ from static methods, which we'll see later are really more like global functions—associated with a class by name only.
Inside a class, we can access variables and call methods of the class directly by name. Here's an example that expands upon our Pendulum:
class Pendulum {
...
void resetEverything( ) {
mass = 1.0;
length = 1.0;
cycles = 0;
...
float startingPosition = getPosition( 0.0 );
}
...
}
Other classes access members of an object through a reference, using the (C-style) dot notation:
class TextBook {
...
void showPendulum( ) {
Pendulum bob = new Pendulum( );
...
int i = bob.cycles;
bob.resetEverything( );
bob.mass = 1.01;
...
}
...
}
Here we have created a second class, TextBook, that uses a Pendulum object. It creates an instance in showPendulum() and then invokes methods and accesses variables of the object through the reference bob.
Several factors affect whether class members can be accessed from "outside" the class (from another class). You can use the visibility modifiers public, private, and protected to control access; classes can also be placed into a package, which affects their scope. The private modifier, for example, designates a variable or method for use only by other members of the class itself. In the previous example, we could change the declaration of our variable cycles to private:
class Pendulum {
...
private int cycles;
...
Now we can't access cycles from TextBook:
class TextBook {
...
void showPendulum( ) {
...
int i = bob.cycles; // Compile time error
If we still need to access cycles in some capacity, we might add a public getCycles() method to the Pendulum class. We'll take a detailed look at packages, access modifiers, and how they affect the visibility of variables and methods in Chapter 6.
As we've said, instance variables and methods are associated with and accessed through an instance of the class—i.e., through a particular object. In contrast, members that are declared with the static modifier live in the class and are shared by all instances of the class. Variables declared with the static modifier are called static variables or class variables; similarly, these kinds of methods are called static methods or class methods. We can add a static variable to our Pendulum example:
class Pendulum {
...
static float gravAccel = 9.80;
...
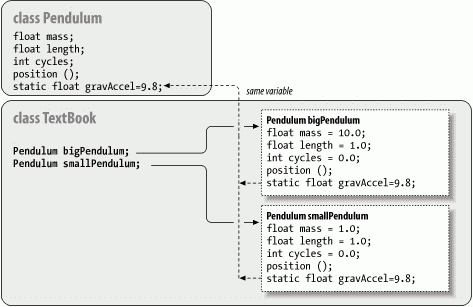
We have declared the new float variable gravAccel as static. That means if we change its value in any instance of a Pendulum, the value changes for all Pendulum objects, as shown in Figure 5-2.
Static members can be accessed like instance members. Inside our Pendulum class, we can refer to gravAccel, like an instance variable:
class Pendulum {
...
float getWeight ( ) {
return mass * gravAccel;
}
...
}
However, since static members exist in the class itself, independent of any instance, we can also access them directly through the class. We don't need a Pendulum object to set the variable gravAccel; instead we can use the class name in place of a reference-type variable:
Pendulum.gravAccel = 8.76;
This changes the value of gravAccel for any current or future instances. Why would we want to change the value of gravAccel? Well, perhaps we want to explore how pendulums would work on different planets. Static variables are also very useful for other kinds of data shared among classes at runtime. For instance, you can create methods to register your objects so that they can communicate, or you can keep track of references to them. It's also common to use static variables to define constant values. In this case, we use the static modifier along with the final modifier. So, if we cared only about pendulums under the influence of the Earth's gravitational pull, we could change Pendulum as follows:
class Pendulum {
...
static final float EARTH_G = 9.80;
...
We have followed a common convention and named our constant with capital letters. Now the value of EARTH_G is a constant; it can be accessed by any instance of Pendulum (or anywhere, for that matter), but its value can't be changed at runtime.
It's important to use the combination of static and final only for things that are really constant. That's because the compiler is allowed to "inline" such values within classes that reference them. This means that if you change a static final variable you may have to recompile all code that uses that class (this is really the only case where you have to do that in Java). Static members are useful as flags and identifiers, which can be accessed from anywhere. They are especially useful for values needed in the construction of an instance itself. In our example, we might declare a number of static values to represent various kinds of Pendulum objects:
class Pendulum {
...
static int SIMPLE = 0, ONE_SPRING = 1, TWO_SPRING = 2;
...
We might then use these flags in a method that sets the type of a Pendulum or, more likely, in a special constructor, as we'll discuss shortly:
Pendulum pendy = new Pendulum( ); pendy.setType( Pendulum.ONE_SPRING );
Again, inside the Pendulum class, we can use static members directly by name, as well; there's no need for the Pendulum. prefix:
class Pendulum {
...
void resetEverything( ) {
setType ( SIMPLE );
...
}
...
}
Methods appear inside class bodies. They contain local variable declarations and other Java statements that are executed by a calling thread when the method is invoked. Method declarations in Java look like ANSI C-style function declarations with two restrictions: a method in Java always specifies a return type (there's no default). The returned value can be a primitive type, a reference type, or the type void , which indicates no returned value. Next, a method always has a fixed number of arguments. The combination of method overloading and true arrays reduces the need for a variable number of arguments, as offered in some languages.
Here's a simple example:
class Bird {
int xPos, yPos;
double fly ( int x, int y ) {
double distance = Math.sqrt( x*x + y*y );
flap( distance );
xPos = x;
yPos = y;
return distance;
}
...
}
In this example, the class Bird defines a method, fly(), that takes as arguments two integers: x and y. It returns a double type value as a result, using the return keyword.
The fly() method declares a local variable called distance, which it uses to compute the distance flown. A local variable is temporary; it exists only within the scope of its method. Local variables are allocated and initialized when a method is invoked; they are normally destroyed when the method returns. They can't be referenced from outside the method itself. If the method is executing concurrently in different threads, each thread has its own copies of the method's local variables. A method's arguments also serve as local variables within the scope of the method.
An object created within a method and assigned to a local variable may or may not persist after the method has returned. As with all objects in Java, it depends on whether any references to the object remain. If an object is created, assigned to a local variable, and never used anywhere else, that object is no longer referenced when the local variable is destroyed, so garbage collection removes the object. If, however, we assign the object to an instance variable, pass it as an argument to another method, or pass it back as a return value, it may be saved by another variable holding its reference. We'll discuss object creation and garbage collection in more detail shortly.
If a local variable and an instance variable have the same name, the local variable shadows or hides the name of the instance variable within the scope of the method. In the following example, the local variables xPos and yPos hide the instance variables of the same name:
class Bird {
int xPos, yPos;
int xNest, yNest;
...
double flyToNest( ) {
int xPos = xNest;
int yPos = yNest:
return ( fly( xPos, yPos ) );
}
...
}
When we set the values of the local variables in flyToNest(), it has no effect on the values of the instance variables.
You can use the special reference this any time you need to refer explicitly to the current object. Often you don't need to use this, because the reference to the current object is implicit; such is the case when using unambiguously named instance variables inside a class. But we can use this to refer explicitly to instance variables in our object, even if they are shadowed. The following example shows how we can use this to allow argument names that shadow instance variable names. This is a fairly common technique, because it saves your having to make up alternative names. Here's how we could implement our fly() method with shadowed variables:
class Bird {
int xPos, yPos;
double fly ( int xPos, int yPos ) {
double distance = Math.sqrt( xPos*xPos + yPos*yPos );
flap( distance );
this.xPos = xPos;
this.yPos = yPos;
return distance;
}
...
}
In this example, the expression this.xPos refers to the instance variable xPos and assigns it the value of the local variable xPos, which would otherwise hide its name. The only reason we need to use this in the previous example is because we've used argument names that hide our instance variables, and we want to refer to the instance variables. You can also use the this reference any time you want to pass a reference to your object to some other method; we'll show examples of that later.
Static methods (class methods), like static variables, belong to the class and not to an individual instance of the class. What does this mean? Well, foremost, a static method lives outside of any particular class instance. It can be invoked by name, through the class name, without any objects around. Because it is not bound to a particular object instance, a static method can directly access only other static members of the class. It can't directly see any instance variables or call any instance methods, because to do so we'd have to ask, "on which instance?" Static methods can be called from instances, just like instance methods, but the important thing is that they can also be used independently.
Our fly() method uses a static method: Math.sqrt(), which is defined by the java.lang.Math class; we'll explore this class in detail in Chapter 10. For now, the important thing to note is that Math is the name of a class and not an instance of a Math object. (It so happens that you can't even make an instance of the Math class.) Because static methods can be invoked wherever the class name is available, class methods are closer to C-style functions. Static methods are particularly useful for utility methods that perform work that is useful either independently of instances or in creating instances. For example, in our Bird class, we could enumerate all types of birds that can be created:
class Bird {
...
static String [] getBirdTypes( ) {
String [] types;
// Create list...
return types;
}
...
}
Here we've defined a static method getBirdTypes(), which returns an array of strings containing bird names. We can use getBirdTypes() from within an instance of Bird, just like an instance method. However, we can also call it from other classes, using the Bird class name as a reference:
String [] names = Bird.getBirdTypes( );
Perhaps a special version of the Bird class constructor accepts the name of a bird type. We could use this list to decide what kind of bird to create.
Static methods also play an important role in various design patterns, where you limit the use of the new operator for a class to one method, a static method called a factory method. We'll talk more about object construction later. But suffice it to say that it's common to see usage like this:
Bird bird = Bird.getBird( "pigeon" );
In the flyToNest() example, we made a point of initializing the local variables xPos and yPos. Unlike instance variables, local variables must be initialized before they can be used. It's a compile-time error to try to access a local variable without first assigning it a value:
void myMethod( ) {
int foo = 42;
int bar;
bar += 1; // compile-time error, bar uninitialized
bar = 99;
bar += 1; // OK here
}
Notice that this doesn't imply local variables have to be initialized when declared, just that the first time they are referenced must be in an assignment. More subtle possibilities arise when making assignments inside conditionals:
void myMethod {
int foo;
if ( someCondition ) {
foo = 42;
...
}
foo += 1; // Compile-time error, foo may not be initialized
}
In this example, foo is initialized only if someCondition is true. The compiler doesn't let you make this wager, so it flags the use of foo as an error. We could correct this situation in several ways. We could initialize the variable to a default value in advance or move the usage inside the conditional. We could also make sure the path of execution doesn't reach the uninitialized variable through some other means, depending on what makes sense for our particular application. For example, we could return from the method abruptly:
int foo;
...
if ( someCondition ) {
foo = 42;
...
} else
return;
foo += 1;
In this case, there's no chance of reaching foo in an uninitialized state, so the compiler allows the use of foo after the conditional.
Why is Java so picky about local variables? One of the most common (and insidious) sources of errors in C or C++ is forgetting to initialize local variables, so Java tries to help us out. If it didn't, Java would suffer the same potential irregularities as C or C++.[2]
Let's consider what happens when you pass arguments to a method. All primitive data types (e.g., int, char, float) are passed by value. By now you're probably used to the idea that reference types (i.e., any kind of object, including arrays and strings) are used through references. An important distinction is that the references themselves (the pointers to these objects) are actually primitive types and are passed by value too.
Consider the following piece of code:
...
int i = 0;
SomeKindOfObject obj = new SomeKindOfObject( );
myMethod( i, obj );
...
void myMethod(int j, SomeKindOfObject o) {
...
}
The first chunk of code calls myMethod(), passing it two arguments. The first argument, i, is passed by value; when the method is called, the value of i is copied into the method's parameter, j. If myMethod() changes the value of j, it's changing only its copy of the local variable.
In the same way, a copy of the reference to obj is placed into the reference variable o of myMethod(). Both references refer to the same object, so any changes made through either reference affect the actual (single) object instance. If we change the value of, say, o.size, the change is visible either as o.size (inside myMethod()) or as obj.size (in the calling method). However, if myMethod() changes the reference o itself—to point to another object—it's affecting only its local variable reference. It doesn't affect the caller's variable obj, which still refers to the original object. In this sense, passing the reference is like passing a pointer in C and unlike passing by reference in C++.
What if myMethod() needs to modify the calling method's notion of the obj reference as well (i.e., make obj point to a different object)? The easy way to do that is to wrap obj inside some kind of object. For example, we could wrap the object up as the lone element in an array:
SomeKindOfObject [] wrapper = new SomeKindOfObject [] { obj };
All parties could then refer to the object as wrapper[0] and would have the ability to change the reference. This is not aesthetically pleasing, but it does illustrate that what is needed is the level of indirection.
Another possibility is to use this to pass a reference to the calling object. In that case, the calling object serves as the wrapper for the reference. Let's look at a piece of code that could be from an implementation of a linked list:
class Element {
public Element nextElement;
void addToList( List list ) {
list.addToList( this );
}
}
class List {
void addToList( Element element ) {
...
element.nextElement = getNextElement( );
}
}
Every element in a linked list contains a pointer to the next element in the list. In this code, the Element class represents one element; it includes a method for adding itself to the list. The List class itself contains a method for adding an arbitrary Element to the list. The method addToList() calls addToList() with the argument this (which is, of course, an Element). addToList() can use the this reference to modify the Element's nextElement instance variable. The same technique can be used in conjunction with interfaces to implement callbacks for arbitrary method invocations.
Method overloading is the ability to define multiple methods with the same name in a class; when the method is invoked, the compiler picks the correct one based on the arguments passed to the method. This implies that overloaded methods must have different numbers or types of arguments. (In Chapter 6, we'll look at method overriding, which occurs when we declare methods with identical signatures in different classes.)
Method overloading (also called ad-hoc polymorphism) is a powerful and useful feature. The idea is to create methods that act in the same way on different types of arguments. This creates the illusion that a single method can operate on any of the types. The print() method in the standard PrintStream class is a good example of method overloading in action. As you've probably deduced by now, you can print a string representation of just about anything using this expression:
System.out.print( argument )
The variable out is a reference to an object (a PrintStream) that defines nine different, "overloaded" versions of the print() method. The versions take arguments of the following types: Object, String, char[], char, int, long, float, double, and boolean.
class PrintStream {
void print( Object arg ) { ... }
void print( String arg ) { ... }
void print( char [] arg ) { ... }
...
}
You can invoke the print() method with any of these types as an argument, and it's printed in an appropriate way. In a language without method overloading, this requires something more cumbersome, such as a uniquely named method for printing each type of object. Then it's your responsibility to remember what method to use for each data type.
In the previous example, print() has been overloaded to support two reference types: Object and String. What if we try to call print() with some other reference type? Say, perhaps, a Date object? When there's not an exact type match, the compiler searches for an acceptable, assignable match. Since Date, like all classes, is a subclass of Object, a Date object can be assigned to a variable of type Object. It's therefore an acceptable match, and the Object method is selected.
What if there's more than one possible match? Say, for example, we tried to print a subclass of String called MyString. (The String class is final, so it can't be subclassed, but please allow this brief transgression for purposes of explanation.) MyString is assignable to either String or to Object. Here the compiler makes a determination as to which match is "better" and selects that method. In this case, it's the String method.
The intuitive explanation is that the String class is closer to MyString in the inheritance hierarchy. It is a more specific match. A more rigorous way of specifying it would be to say that a given method is more specific than another method if the argument types of the first method are all assignable to the argument types of the second method. In this case, the String method is more specific to a subclass of String than the Object method because type String is assignable to type Object. The reverse is not true.
If you're paying close attention, you may have noticed we said that the compiler resolves overloaded methods. Method overloading is not something that happens at runtime; this is an important distinction. It means that the selected method is chosen once, when the code is compiled. Once the overloaded method is selected, the choice is fixed until the code is recompiled, even if the class containing the called method is later revised and an even more specific overloaded method is added. This is in contrast to overridden methods, which are located at runtime and can be found even if they didn't exist when the calling class was compiled. We'll talk about method overriding later in the chapter.
One last note about overloading. In earlier chapters, we've pointed out that Java doesn't support programmer-defined overloaded operators and that + is the only system-defined overloaded operator. If you've been wondering what an overloaded operator is, we can finally clear up that mystery. In a language like C++, you can customize operators such as + and * to work with objects that you create. For example, you could create a class Complex that implements complex numbers and then overload methods corresponding to + and * to add and multiply Complex objects. Some people argue that operator overloading makes for elegant and readable programs, while others say it's just "syntactic sugar" that makes for obfuscated code. The Java designers clearly espoused the latter opinion when they chose not to support programmer-defined overloaded operators.
Objects in Java are allocated on a system "heap" memory space, much like that in C or C++. Unlike in C or C++, however, we needn't manage that memory ourselves. Java takes care of memory allocation and deallocation for you. Java explicitly allocates storage for an object when you create it with the new operator. More importantly, objects are removed by garbage collection when they're no longer referenced.
Objects are allocated with the new operator using an object constructor. A constructor is a special method with the same name as its class and no return type. It's called when a new class instance is created, which gives the class an opportunity to set up the object for use. Constructors, like other methods, can accept arguments and can be overloaded (they are not, however, inherited like other methods; we'll discuss inheritance in Chapter 6).
class Date {
long time;
Date( ) {
time = currentTime( );
}
Date( String date ) {
time = parseDate( date );
}
...
}
In this example, the class Date has two constructors. The first takes no arguments; it's known as the default constructor. Default constructors play a special role: if we don't define any constructors for a class, an empty default constructor is supplied for us. The default constructor is what gets called whenever you create an object by calling its constructor with no arguments. Here we have implemented the default constructor so that it sets the instance variable time by calling a hypothetical method, currentTime(), which resembles the functionality of the real java.util.Date class. The second constructor takes a String argument. Presumably, this String contains a string representation of the time that can be parsed to set the time variable. Given the constructors in the previous example, we create a Date object in the following ways:
Date now = new Date( );
Date christmas = new Date("Dec 25, 2002");
In each case, Java chooses the appropriate constructor at compile time based on the rules for overloaded method selection.
If we later remove all references to an allocated object, it'll be garbage-collected, as we'll discuss shortly:
christmas = null; // fair game for the garbage collector
Setting this reference to null means it's no longer pointing to the "Dec 25, 2002" object. (So would setting christmas to any other value.) Unless that object is referenced by another variable, it's now inaccessible and can be garbage-collected.
A few more notes: constructors can't be declared abstract, synchronized, or final (we'll define the rest of those terms later). Constructors can, however, be declared with the visibility modifiers public, private, or protected to control their accessibility. We'll talk in detail about visibility modifiers in the next chapter.
A constructor can refer to another constructor in the same class or the immediate superclass using special forms of the this and super references. We'll discuss the first case here, and return to that of the superclass constructor after we have talked more about subclassing and inheritance. A constructor can invoke another, overloaded constructor in its class using the reference this() with appropriate arguments to select the desired constructor. If a constructor calls another constructor, it must do so as its first statement:
class Car {
String model;
int doors;
Car( String m, int d ) {
model = m;
doors = d;
// other, complicated setup
...
}
Car( String m ) {
this( m, 4 );
}
...
}
In this example, the class Car has two constructors. The first, more explicit one, accepts arguments specifying the car's model and its number of doors. The second constructor takes just the model as an argument and, in turn, calls the first constructor with a default value of four doors. The advantage of this approach is that you can have a single constructor do all the complicated setup work; other auxiliary constructors simply feed the appropriate arguments to that constructor.
The call to this() must appear as the first statement in our second constructor. The syntax is restricted in this way because there's a need to identify a clear chain of command in the calling of constructors. At one end of the chain, Java invokes the constructor of the superclass (if we don't do it explicitly) to ensure that inherited members are initialized properly before we proceed.
There's also a point in the chain, just after the constructor of the superclass is invoked, where the initializers of the current class's instance variables are evaluated. Before that point, we can't even reference the instance variables of our class. We'll explain this situation again in complete detail after we have talked about inheritance.
For now, all you need to know is that you can invoke a second constructor only as the first statement of another constructor. For example, the following code is illegal and causes a compile-time error:
Car( String m ) {
int doors = determineDoors( );
this( m, doors ); // Error: constructor call
// must be first statement
}
The simple model name constructor can't do any additional setup before calling the more explicit constructor. It can't even refer to an instance member for a constant value:
class Car {
...
final int default_doors = 4;
...
Car( String m ) {
this( m, default_doors ); // Error: referencing
// uninitialized variable
}
...
}
The instance variable defaultDoors is not initialized until a later point in the chain of constructor calls, so the compiler doesn't let us access it yet. Fortunately, we can solve this particular problem by using a static variable instead of an instance variable:
class Car {
...
static final int DEFAULT_DOORS = 4;
...
Car( String m ) {
this( m, DEFAULT_DOORS ); // Okay now
}
...
}
The static members of a class are initialized when the class is first loaded, so it's safe to access them in a constructor.
It's possible to declare a block of code (some statements within curly braces) directly within the scope of a class. This code block doesn't belong to any method; instead, it's executed once, at the time the object is constructed, or, in the case of a code block marked static, at the time the class is loaded. These blocks can be used to do additional setup for the class or an object instance and are sometimes called initializer blocks.
Instance initializer blocks can be thought of as extensions of instance variable initialization. They're called at the time the instance variable's initializers are evaluated (after superclass construction), in the order that they appear in the Java source:
class MyClass {
Properties myProps = new Properties( );
// set up myProps
{
myProps.put("foo", "bar");
myProps.put("boo", "gee");
}
int a = 5;
...
Normally this kind of setup could be done just as well in the object's constructor. A notable exception is in the case of an anonymous inner class (see Chapter 6).
Similarly, you can use static initializer blocks to set up static class members. This allows the static members of a class to have complex initialization just like objects do with constructors:
class ColorWheel {
static Hashtable colors = new Hashtable( );
// set up colors
static {
colors.put("Red", Color.red );
colors.put("Green", Color.green );
colors.put("Blue", Color.blue );
...
}
...
}
The class ColorWheel provides a variable colors that maps the names of colors to Color objects in a Hashtable. The first time the class ColorWheel is referenced and loaded, the static components of ColorWheel are evaluated, in the order they appear in the source. In this case, the static code block simply adds elements to the colors Hashtable.
Now that we've seen how to create objects, it's time to talk about their destruction. If you're accustomed to programming in C or C++, you've probably spent time hunting down memory leaks in your code. Java takes care of object destruction for you; you don't have to worry about memory leaks, and you can concentrate on more important programming tasks.
Java uses a technique known as garbage collection to remove objects that are no longer needed. The garbage collector is Java's grim reaper. It lingers, usually in a low-priority thread, stalking objects and awaiting their demise. It finds them and watches them, periodically counting references to them to see when their time has come. When all references to an object are gone, and it's no longer accessible, the garbage-collection mechanism declares the object unreachable and reclaims its space back to the available pool of resources. An unreachable object is one that cannot be found through any references in the running application.
There are many different algorithms for garbage collection; the Java virtual machine architecture doesn't require a particular scheme. It's worth noting, however, by way of example, how some implementations of Java accomplish this task. Under a scheme called "mark and sweep," Java first walks through the tree of all accessible object references and marks them as alive. Then Java scans the heap looking for identifiable objects that aren't marked. In this scenario, Java is able to find objects on the heap because they are stored in a characteristic way and have a particular signature of bits in their handles unlikely to be reproduced naturally. This kind of algorithm doesn't become confused by the problem of cyclic references, in which detached objects can mutually reference each other and appear alive (and that behavior is guaranteed by Java). It did, however, slow Java's execution and so in Java 1.3, Sun implemented a new garbage collection method.
As of Java 1.3, garbage collection effectively runs continuously in a very efficient way that should never cause a significant delay in execution. Java garbage collectors use state-of-the-art techniques to balance efficiency of collection with performance and to minimize interruption of your application. The improvement in Java's garbage collection since the early releases has been remarkable and is one of the reasons that Java is now competitive with traditional compiled languages in terms of speed.
In general you do not have to concern yourself with the garbage-collection process. But there is one method that can be useful for debugging. You can prompt the garbage collector to make a sweep explicitly by invoking the System.gc() method. This method is somewhat implementation-dependent but could be used if you want to guarantee that Java has cleaned up before you do some activity.
Before an object is removed by garbage collection, its finalize() method is invoked to give it a last opportunity to clean up its act and free other kinds of resources it may be holding. While the garbage collector can reclaim memory resources, it may not take care of things such as closing files and terminating network connections as gracefully or efficiently as could your code. That's what the finalize() method is for. An object's finalize() method is called once and only once before the object is garbage-collected. However, there's no guarantee when that will happen. Garbage collection may, in theory, never run on a system that is not short of memory. It is also interesting to note that finalization and collection occur in two distinct phases of the garbage-collection process. First items are finalized; then they are collected. It is therefore possible that finalization can (intentionally or unintentionally) create a lingering reference to the object in question, postponing its garbage collection. The object is, of course, subject to collection later, if the reference goes away, but its finalize() method isn't called again.
The finalize() methods of superclasses are not invoked automatically for you. If you need to invoke the finalization routine of your parent classes, you should invoke the finalize() method of your superclass, using super.finalize(). We discuss inheritance and overridden methods in Chapter 6.
In general, as we've described, Java's garbage collector reclaims objects when they are unreachable. An unreachable object, again, is one that is no longer referenced by any variables within your application, one that is not reachable through any chain of references by any running thread. Such an object cannot be used by the application any longer and is therefore a clear case where the object should be removed.
There are, however, situations where it is advantageous to have Java's garbage collector work with your application to decide when it is time to remove a particular object. For these cases, Java allows you to hold an object reference indirectly through a special wrapper object, a type of java.lang.ref.Reference. If Java then decides to remove the object, the reference the wrapper holds turns to null automatically. But while the reference exists, you may continue to use it in the ordinary way and if you wish, assign it elsewhere (using normal references), preventing its garbage collection.
There are two types of Reference wrappers that implement different schemes for deciding when to let their target references be garbage-collected. The first is called a WeakReference. Weak references are eligible for garbage collection immediately; they do not prevent garbage collection the way that ordinary "strong" references do. This means that if you have a combination of strong references and references contained in WeakReference wrappers in your application, the garbage collector waits until only WeakReferences remain and then collects the object. This is an essential feature that allows garbage collection to work with certain kinds of caching schemes. Often you'll want to cache an object reference for performance (to avoid creating it or looking it up). But unless you take specific action to remove unneeded objects from your cache, the cache keeps those objects alive forever by maintaining live references to them. By using weak references, you can implement a cache that automatically throws away references when the object would normally be garbage-collected. In fact, an implementation of HashMap called WeakHashMap is provided that does just this (see Chapter 10 for details).
The second type of reference wrapper is called SoftReference. A soft reference is similar to a weak reference, but it tells the garbage collector to be less aggressive about reclaiming its contents. Soft-referenced objects are collected only when and if Java runs short of memory. This is useful for a slightly different kind of caching where you want to keep some content around unless there is a need to get rid of it. For example, a web browser can use soft references to cache images or HTML strings internally, thus keeping them around as long as possible until memory constraints come into play. (A more sophisticated application might also use its own scheme based on "least recently used" marking of some kind.)
The java.lang.ref package contains the WeakReference and SoftReference wrappers, as well as a facility called ReferenceQueue that allows your application to receive a list of references that have been collected. It's important that your application use the queue or some other checking mechanism to remove the Reference objects themselves after their contents have been collected; otherwise your cache will soon fill up with empty Reference object wrappers.
[1] Once you have some experience with basic object-oriented concepts, you might want to take a look at Design Patterns: Elements of Reusable Object-Oriented Software by Gamma, Helm, Johnson, and Vlissides (Addison-Wesley). This book catalogs useful object-oriented designs that have been refined over the years by experience. Many appear in the design of the Java APIs.
[2] As with malloc'ed storage in C or C++, Java objects and their instance variables are allocated on a heap, which allows them default values once, when they are created. Local variables, however, are allocated on the Java virtual machine stack. As with the stack in C and C++, failing to initialize these could mean successive method calls could receive garbage values, and program execution might be inconsistent or implementation-dependent.
| CONTENTS |